
Bullying Classification
1. Background
The Department of Education conducts a periodic survey of public schools in the country: The School Survey on Crime and Safety (SSOCS). More information on this survey can be found here. For this project, I downloaded cross-sectional data from the 2015-2016 school year. The relevant files are available directly in my GitHub repository, although they can also be manually downloaded from the National Center for Education Statistics (NCES) website. After some preliminary analysis, I chose to focus on three main questions:
- Is it possible to predict how many violent incidents a school will have in a given year?
- Is it possible to predict the extent to which bullying occurs at a school?
- Is there discrimination based on race when it comes to disciplinary action at schools?
This notebook will focus on developing insights for the second question above.
The analysis resulted in the following conclusions:
- The random forest model performed the best.
- More flexible models performed better than more standard models, suggesting some non-linearity/interaction between features.
- The largest misclassifications were in predicting 4 instead of 3, 4 instead of 2, and 3 instead of 4. This suggests that the dominance of the majority class value 4 is making it difficult to accurately predict the minority classes.
2. Setup/Data Cleaning
The following module needs to be installed in order to read the original data file:
pip install sas7bdatimport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
from sas7bdat import SAS7BDAT
%matplotlib inline
pd.options.display.max_columns = 17reader = SAS7BDAT('school_safety.sas7bdat', skip_header=False)
school_df = reader.to_data_frame()
y_classification = school_df["C0376"]From the below bar graph, it is evident that the target variable has an uneven class distribution. In order to ensure my ML algorithms were able to more accurately predict the underrepresented classes, I decided to incorporate oversampling on my training set. I also ensured my train and test set had equal proportions of each of the 5 categorical values and used stratified k-fold cross-validation.
y_classification.value_counts().sort_index().plot.bar(figsize=(16,12))
In School Safety – Part 1, I removed any rows corresponding to target outliers (violent indicents > 31). Given that I used oversampling for this classification problem, it did not make sense to drop rows like before. I loaded the feature dataframe from Part 1, isolated the VIF reduced variable names, and re-filtered columns of the original school_df without dropping any rows.
#Load feature dataframe from "School Safety - Part 1"
feature_df_part_1 = pd.read_csv("feature_df_regression.csv", index_col = 0)
part_1_features = feature_df_part_1.columns
feature_df = school_df[part_1_features]
#Select binary columns
binary_cols = [col for col in feature_df.columns if feature_df[col].isin([1,2]).all()]
#Select non-binary columns
non_binary_cols = [col for col in feature_df.columns if not feature_df[col].isin([1,2]).all()]#Convert non-binary categorical columns to custom values
#1 if city else 0
feature_df["FR_URBAN"] = feature_df["FR_URBAN"].apply(lambda x: 1 if x==1 else 0)
#1 if high school else 0
feature_df["FR_LVEL"] = feature_df["FR_LVEL"].apply(lambda x: 1 if x==3 else 0)
#1 if >=500 students else 0
feature_df["FR_SIZE"] = feature_df["FR_SIZE"].apply(lambda x: 1 if x in [3,4] else 0)#Convert Y/N columns to 0 or 1
feature_df[binary_cols] = feature_df[binary_cols].applymap(lambda x: 1 if x==1 else 0)#I exported the final feature dataframe to a CSV file for easy access. File available on my GitHub.
feature_df = pd.read_csv("feature_df_classification.csv",index_col=0)
#Recalculate binary vs non-binary columns
binary_cols = [col for col in feature_df.columns if feature_df[col].isin([0,1]).all()]
non_binary_cols = [col for col in feature_df.columns if not feature_df[col].isin([0,1]).all()]3. Predictive Modeling
In this section, I trained several different machine learning models to see if the features from School Safety – Part 1 could be used to make predictions about which category bullying fell into at US public school. I chose the weighted-F1 score as my primary metric for evaluating model performance.
3.1. Data Split, Scaling, and SMOTE-NC
I began by splitting my data into a train and test set, setting 20% of the entries aside as test data. In order to ensure I was able to make maximal use of my available data, I incorporated k-fold cross validation with 5 folds rather than setting aside another 20% of entries for a separate cross validation set.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(feature_df, y_classification,
test_size=0.2, random_state=5,
stratify=y_classification)
from sklearn.model_selection import StratifiedKFold
kf = StratifiedKFold(n_splits=5, shuffle=True, random_state=10)Just like in Part 1, I had to standardize non-binary columns in order to ensure models would converge quickly and KNN would not be influenced by variable scale.
from sklearn.preprocessing import StandardScaler
#We will only scale non-binary columns
scaler = StandardScaler()
X_train_scaled = X_train
X_test_scaled = X_test
X_train_scaled[non_binary_cols] = scaler.fit_transform(X_train[non_binary_cols])
col_mean = scaler.mean_
col_std = (scaler.var_)**.5
X_test_scaled[non_binary_cols] = (X_test[non_binary_cols]-col_mean)/col_stdNext, I used the synthetic minority oversampling technique (SMOTE) which required installation of the following module:
pip install imbalanced-learnThis technique generates additional samples from the non-majority classes so that the resulting data set has an equal representation for all classes. These additional samples are not simply copies of existing rows. Instead, the algorithm utilizes a nearest neighbors approach to synthesize new data points. In this project, SMOTE drastically increases the number of rows in the training set.
A major challenge that arose was how to incorporate SMOTE into grid search and cross-fold validation. The synthetically generated training samples depend on the original training set. As a result, my decision to use 5 stratified folds essentially meant that 5 different SMOTE generated training sets would be needed. The below code solves this issue by generating a SMOTE training set for each of the 5 folds and saving the corresponding SMOTE training vs cross-validation indices into the cv_indices list.
from imblearn.over_sampling import SMOTENC
categorical_features = [True if col in binary_cols else False for col in X_train_scaled.columns]
sm = SMOTENC(categorical_features=categorical_features, random_state= 7)
X_train_custom = X_train_scaled.reset_index(drop=True)
y_train_custom = y_train.reset_index(drop=True)
num_rows_original = X_train_custom.shape[0]
smote_indices = []
cv_indices = []
fold_num=0
for train_index, cv_index in kf.split(X_train_custom,y_train_custom):
num_rows_fold_original = len(train_index)
X_train_smote_fold, y_train_smote_fold = sm.fit_sample(X_train_custom.iloc[train_index],
y_train_custom.iloc[train_index])
X_train_smote_fold = X_train_smote_fold.iloc[num_rows_fold_original:]
y_train_smote_fold = y_train_smote_fold.iloc[num_rows_fold_original:]
X_train_custom = pd.concat([X_train_custom,X_train_smote_fold],ignore_index=True)
y_train_custom = pd.concat([y_train_custom,y_train_smote_fold],ignore_index=True)
if fold_num==0:
smote_indices.append([*range(num_rows_original,num_rows_original+X_train_smote_fold.shape[0])])
else:
last_row = smote_indices[-1][-1]
smote_indices.append([*range(last_row+1,last_row+1+X_train_smote_fold.shape[0])])
train_index_fold = np.append(train_index,smote_indices[fold_num])
cv_index_fold = cv_index
cv_indices.append((train_index_fold,cv_index_fold))
fold_num+=1Finally, I ran SMOTE on the entire training set (without leaving any data out for cross-validation).
X_train_smote, y_train_smote = sm.fit_sample(X_train_scaled, y_train)
y_train_smote.value_counts()1.0 1005
5.0 1005
3.0 1005
2.0 1005
4.0 1005
Name: C0376, dtype: int643.2. Logistic Regression
The following models incorporate variations of logistic regression. First, I ran a standard logistic regression on the entire feature set. In order to address overfitting, I next constructed a recursive feature elimination regression.
3.2.1. Standard Logistic Regression
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
log_params = {"penalty":["l1","l2"],
"C":[.0001,.001,.01,.1,1,10,100,1000,3333,10000,33333,100000],
"random_state":[20],
"solver":["liblinear"],
"max_iter":[1000]}
log = LogisticRegression()
log_grid = GridSearchCV(estimator=log,
param_grid=log_params,
scoring="f1_weighted",
cv=cv_indices)
log_grid.fit(X_train_custom, y_train_custom)log_grid.best_params_{'C': 10,
'max_iter': 1000,
'penalty': 'l1',
'random_state': 20,
'solver': 'liblinear'}log_grid.best_score_0.43650983991224823log = log_grid.best_estimator_
log.fit(X_train_smote,y_train_smote)
log_coef = pd.DataFrame(log.coef_)
log_coef.columns = X_train_smote.columns
log_features = log_coef.columns[log_coef.mean()!=0]
len(log_features) #73 non-zero features3.2.2. Logistic Regression with Recursive Feature Elimination
from sklearn.feature_selection import RFECV
rfe_df = pd.DataFrame()
for C in [.0001,.001,.01,.1,1,10,100,1000,3333,10000,33333,100000]:
for penalty in ["l1","l2"]:
log_rfe = LogisticRegression(C=C,penalty=penalty,max_iter=5000,random_state=20,solver="liblinear")
selector = RFECV(log_rfe, cv=cv_indices, scoring="f1_weighted")
selector.fit(X_train_custom, y_train_custom)
n_features = selector.n_features_
features = selector.support_
best_score = max(selector.grid_scores_)
rfe_df = rfe_df.append({"C":C,"penalty":penalty,"n_features":n_features,
"features":features,"best_score":best_score},ignore_index=True)rfe_df.sort_values(by="best_score",ascending=False)
rfe_features = rfe_df.loc[8,"features"]
log_rfe = LogisticRegression(C=1,penalty="l1",max_iter=5000,random_state=20,solver="liblinear")
log_rfe.fit(X_train_smote.loc[:,rfe_features],y_train_smote)
log_rfe_coef = pd.DataFrame(log_rfe.coef_)
log_rfe_coef.columns = X_train_smote.loc[:,rfe_features].columns
log_rfe_features = log_rfe_coef.columns[log_rfe_coef.mean()!=0]
len(log_rfe_features) #66 non-zero features3.3. K-Nearest Neighbors
While the above logistic regressions were quite promising, I wanted to see if other ML models would result in better performance. I next built a KNN model on the standard logistic regression feature set and the RFE selected feature set.
3.3.1. KNN on Standard Feature Set
from sklearn.neighbors import KNeighborsClassifier
knn_params = {"n_neighbors" : [2,4,8,16,32,64,128,256,512],
"weights" : ["uniform", "distance"],
"p" : [1,2]}
knn = KNeighborsClassifier()
knn_grid = GridSearchCV(estimator=knn,
param_grid=knn_params,
scoring="f1_weighted",
cv=cv_indices)
knn_grid.fit(X_train_custom[log_features], y_train_custom)knn_grid.best_params_{'n_neighbors': 2, 'p': 1, 'weights': 'distance'}
knn_grid.best_score_0.3486041126060394
3.3.2. KNN on RFE Feature Set
knn_rfe_grid = GridSearchCV(estimator=knn,
param_grid=knn_params,
scoring="f1_weighted",
cv=cv_indices)
knn_rfe_grid.fit(X_train_custom.loc[:,rfe_features], y_train_custom)knn_rfe_grid.best_params_{'n_neighbors': 2, 'p': 2, 'weights': 'distance'}
knn_rfe_grid.best_score_0.3680564866530543.4. Support Vector Machine
from sklearn.svm import SVC
svm_params = {"C":[.0001,.001,.01,.1,1,10,100,1000],
"kernel":["poly","rbf"],
"degree":[2,3]}
svm = SVC()
svm_grid = GridSearchCV(estimator=svm,
param_grid=svm_params,
scoring="f1_weighted",
cv=cv_indices,
verbose=3)
svm_grid.fit(X_train_custom, y_train_custom)svm_grid.best_params_{'C': 0.1, 'degree': 2, 'kernel': 'rbf'}
svm_grid.best_score_0.482391545774782773.5. Random Forest
from sklearn.ensemble import RandomForestClassifier
rf_params = {"n_estimators" : [300],
"max_depth" : [2,4,8,16,32,64,128,None],
"max_features" : ["sqrt", "log2", .1, .25, .5, 5, 10, 25],
"min_samples_leaf" : [1,3,5],
"random_state" : [10]}
rf = RandomForestClassifier()
rf_grid = GridSearchCV(estimator=rf,
param_grid=rf_params,
scoring="f1_weighted",
cv=cv_indices,
verbose=3)
rf_grid.fit(X_train_custom, y_train_custom)rf_grid.best_params_{'max_depth': 32,
'max_features': 'sqrt',
'min_samples_leaf': 1,
'n_estimators': 300,
'random_state': 10}rf_grid.best_score_0.49108422293523885
3.6. Neural Network
Given the computational requirements of multi-layer neural networks, the following block of code took quite some time to run.
from sklearn.neural_network import MLPClassifier
nn_params = {"hidden_layer_sizes" : [(100,),(100,100)],
"activation" : ["logistic", "tanh", "relu"],
"alpha" : [.00001,.0001,.001,.01,.1,1.0,10,100,1000],
"max_iter" : [2500],
"random_state" : [10],
"warm_start" : [True]}
nn = MLPClassifier()
nn_grid = GridSearchCV(estimator=nn,
param_grid=nn_params,
scoring="f1_weighted",
cv=cv_indices)
nn_grid.fit(X_train_custom, y_train_custom)nn_grid.best_params_{'activation': 'tanh',
'alpha': 1e-05,
'hidden_layer_sizes': (100,),
'max_iter': 2500,
'random_state': 10,
'warm_start': True}nn_grid.best_score_0.466283678323762443.7. Model Selection and Interpretation
The results of the above models are summarized in the table below (ordered from best to worst performance):
models = ["Logistic Regression - Standard",
"Logistic Regression - RFE",
"K-Nearest Neighbors - Standard",
"K-Nearest Neighbors - RFE",
"Support Vector Machine",
"Random Forest",
"Neural Network"]
optimized_parameters = [log_grid.best_params_,
{'n_features':66,'C':1,'max_iter':1000,'penalty':'l1','random_state':20,'solver':'liblinear'},
knn_grid.best_params_,
knn_rfe_grid.best_params_,
svm_grid.best_params_,
rf_grid.best_params_,
nn_grid.best_params_]
F1 = [log_grid.best_score_,
0.438245,
knn_grid.best_score_,
knn_rfe_grid.best_score_,
svm_grid.best_score_,
rf_grid.best_score_,
nn_grid.best_score_]
model_df = pd.DataFrame({"model" : models,
"optimized_parameters" : optimized_parameters,
"weighted-F1" : F1})
with pd.option_context('display.max_colwidth', 150):
display(model_df.sort_values(by="weighted-F1",ascending=False))
The random forest model performed the best. More flexible models performed better than more standard models, suggesting some non-linearity/interaction between features. I ran the random forest model with the optimized parameters on the test set for a final assessment of weighted-F1.
#Fit model to entire SMOTE training set
model_best = RandomForestClassifier(max_depth=32,max_features="sqrt",n_estimators=300,random_state=10)
model_best.fit(X_train_smote,y_train_smote)
#Predict test values
y_pred = model_best.predict(X_test)
#Calculate weighted-F1
from sklearn.metrics import f1_score
f1_score(y_test,y_pred,average="weighted")0.46170242918007665Next, I built a confusion matrix. The model never correctly predicted values of 1 or 5. The largest misclassifications were in predicting 4 instead of 3, 4 instead of 2, and 3 instead of 4. This suggests that even with SMOTE-NC, the dominance of the majority class value 4 is making it difficult to accurately predict the minority classes.
from sklearn.metrics import confusion_matrix
sns.set(font_scale=1.6)
cm = confusion_matrix(y_test, y_pred)
fig, ax = plt.subplots(figsize=(16,12))
sns.heatmap(cm, annot=True, ax = ax, fmt="d")
ax.set_xlabel('Predicted')
ax.set_ylabel('True')
ax.set_title('Confusion Matrix')
ax.xaxis.set_ticklabels([1,2,3,4,5])
ax.yaxis.set_ticklabels([1,2,3,4,5])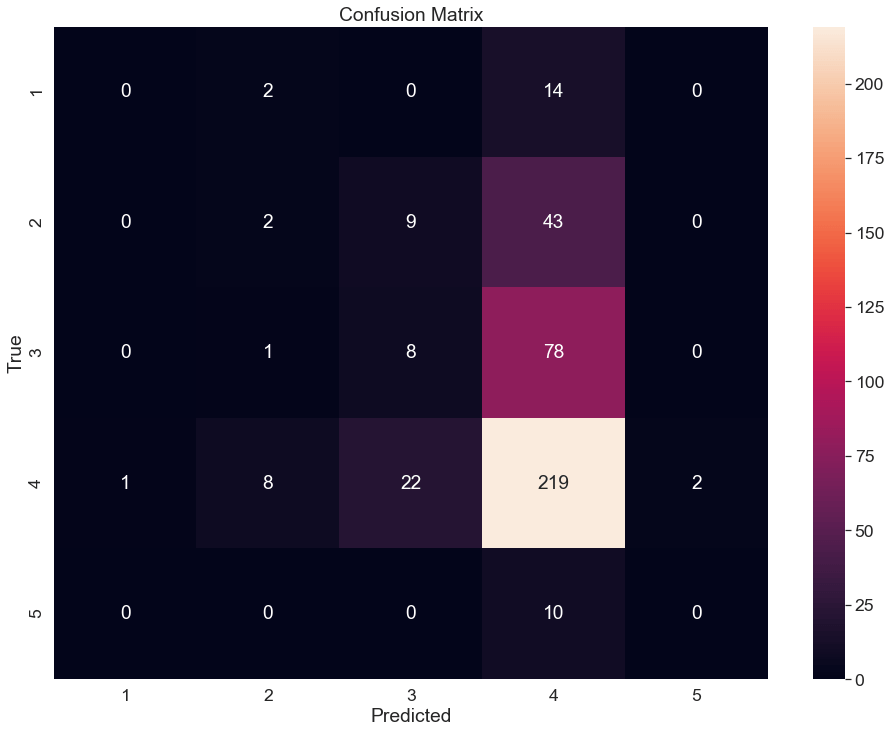
For the random forest model, interpretation of which variables affect bullying classification is not immediately obvious. Fortunately, there is a package that addresses this issue:
pip install treeinterpreterFor each test row, this module splits the classification probabilities into a bias and feature contribution array. The predicted probability for each class is (bias array) + (feature_contribution array * feature value).
I also copied over the variable name lookup function from Part 1 to assist. Below, I displayed the top features contributing to the probability of each predicted class.
cols_to_keep_df = pd.read_csv("column_filter.csv")
def col_description_lookup(col_list):
result = pd.DataFrame({"Variable" : col_list})
result = result.merge(cols_to_keep_df[["Variable", "Label"]], how="left", on="Variable")
return resultfrom treeinterpreter import treeinterpreter as ti
prediction, bias, contributions = ti.predict(model_best, X_test)
contributions_df = pd.DataFrame(contributions.mean(axis=0))
contributions_df = contributions_df.set_index(X_test.columns)
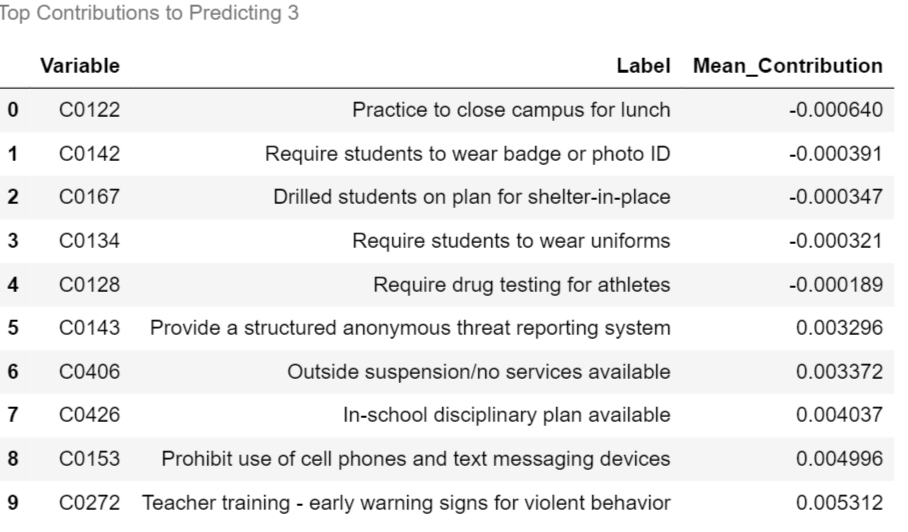
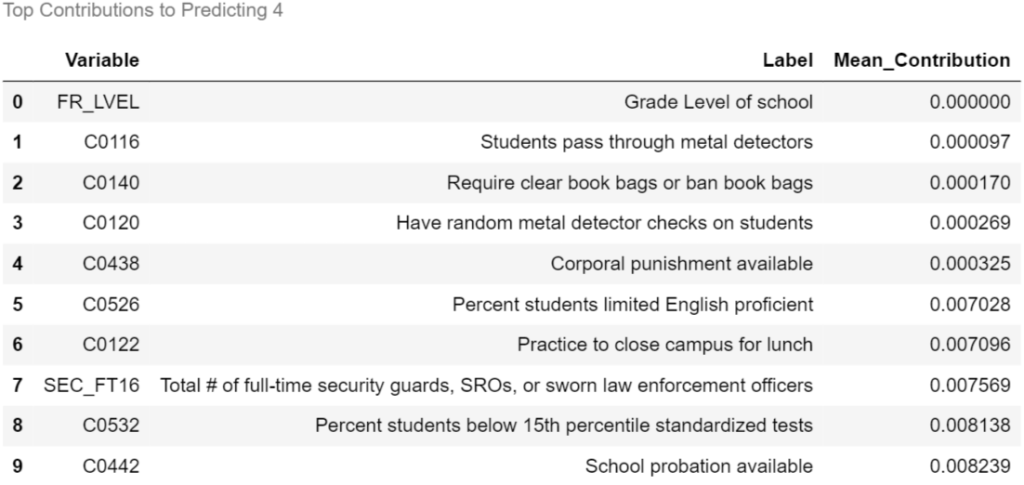
contributions_df.columns = [1,2,3,4,5]for label, contribution in contributions_df.items():
biggest_contribution = contribution.sort_values().iloc[[0,1,2,3,4,-5,-4,-3,-2,-1]]
with pd.option_context('display.max_colwidth',150):
result = col_description_lookup(biggest_contribution.index)
result['Mean_Contribution'] = biggest_contribution.values
result = result.style.set_caption("Top Contributions to Predicting "+str(label))
display(result)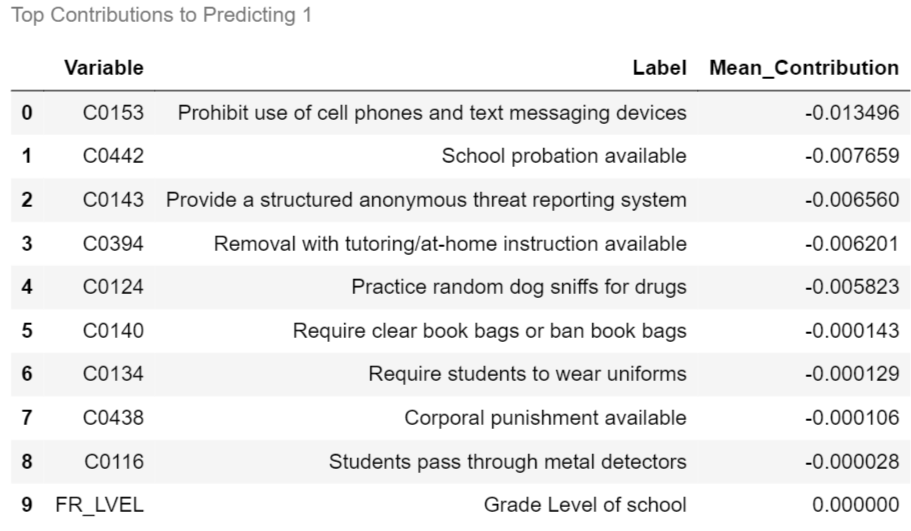


4. Conclusion/Further Steps
The chosen random forest model had trouble identifying minority classes even though SMOTE-NC was incorporated during training. The weighted-F1 score of .46 on the test set would need to be improved a bit before I would be confident using this model on unseen data.
As a first additional step, I would conduct error analysis by randomly choosing some misclassified schools. If a pattern was evident as to why schools were consistently misclassified, I could adjust the model/add more complicated features to improve it. Second, I would focus on reducing model variance by gathering data from additional schools, particularly schools belonging to minority bullying classes. In practice, this would be very difficult without government cooperation, as survey responses have been anonymized so there is no way to know which schools have already been surveyed.
It would also be interesting to try to classify schools based off other categorical target variables included in the survey, such as sexual harassment, racial tensions, etc.
