
Data Preparation and Violence Regression
1. Background
The US government makes many datasets publically available, and I had a particular interest in school safety. While the media often highlights tragic cases of gun violence, I wanted to dig deeper and see if there was anything to be learned about crime and safety in general at schools. Forunately, the Department of Education conducts a periodic survey of public schools in the country: The School Survey on Crime and Safety (SSOCS). More information on this survey can be found here. For this project, I downloaded cross-sectional data from the 2015-2016 school year. The relevant files are available directly in my GitHub repository, although they can also be manually downloaded from the National Center for Education Statistics (NCES) website. After some preliminary analysis, I chose to focus on three main questions:
- Is it possible to predict how many violent incidents a school will have in a given year?
- Is it possible to predict the extent to which bullying occurs at a school?
- Is there discrimination based on race when it comes to disciplinary action at schools?
This notebook will focus on cleaning/exploring the data and developing insights for the first question above.
The analysis resulted in the following conclusions:
- OLS with RFE was the best model.
- Drug testing, required faculty ID, teacher training on substance abuse, and community involvement in school safety were all associated with a reduction in violent incidents.
- Larger schools were associated with more violent incidents.
- Metal detectors, required student IDs, required clear book bags/book bag bans, and presence of law enforcement were associated with an increase in violent incidents (correlation does not imply causation).
2. Setup/Data Cleaning
The following module needs to be installed in order to read the original data file:
pip install sas7bdatimport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
from sas7bdat import SAS7BDAT
%matplotlib inline
pd.options.display.max_columns = 17#Load the full data file into a dataframe
reader = SAS7BDAT('school_safety.sas7bdat', skip_header=False)
school_df = reader.to_data_frame()
#Load the target variable of interest into a series
#VIOINC16 = Total number of violent incidents recorded
y_regression = school_df["VIOINC16"]Given that I was running a regression on the total number of violent incidents at schools, I suspected that the target variable would contain many outliers. My first step was to visualize the data and remove any outliers that would prove troublesome for machine learning algorithms
y_regression.hist(bins=100, figsize=(12,9))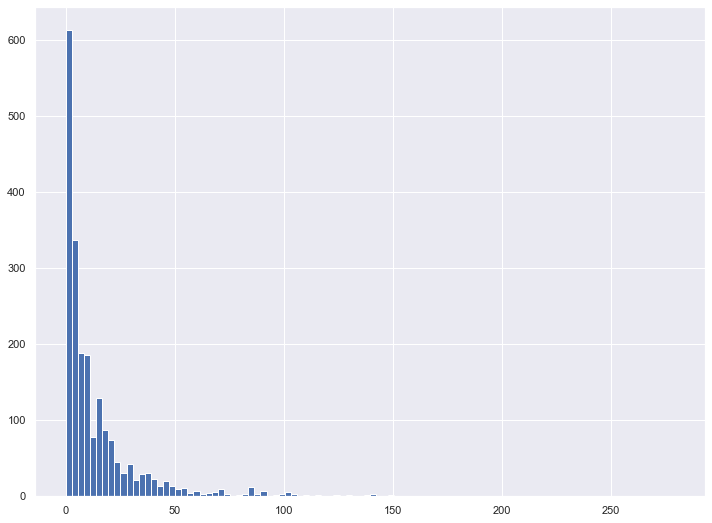
y_regression.plot.box(figsize=(12,9))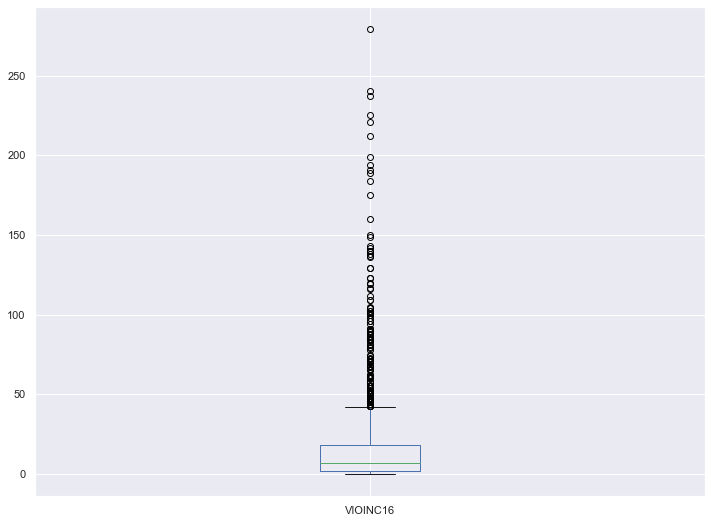
from scipy.stats import iqr
#An observation is considered an outlier if it lies more than 1.5 * IQR from the median
upper_bound = y_regression.median() + 1.5 * iqr(y_regression)
lower_bound = y_regression.median() - 1.5 * iqr(y_regression)
print("Upper Bound: " + str(upper_bound))
print("Lower Bound: " + str(lower_bound))Upper Bound: 31.0
Lower Bound: -17.0print("Number of Target Points: " + str(len(y_regression)))
print("Number of Outliers: " + str(sum(y_regression > upper_bound)))
print("Percent Outliers: " + str(sum(y_regression > upper_bound)/len(y_regression)))Number of Target Points: 2092
Number of Outliers: 278
Proportion Outliers: 0.13288718929254303Eliminating all 278 outliers unfortunately reduced my dataset by more than 10%, which isn’t ideal given I didn’t have an abundance of schools to start with. However, after running this analysis with different upper bound cutoffs, I decided it made sense to limit the data set to schools with 31 or fewer violent incidents.
y_regression_reduced = y_regression[y_regression <= 31]Next, it was time to develop a dataframe of features. I removed any rows corresponding to outliers as calculated above.
school_df_reduced = school_df.iloc[y_regression_reduced.index, :]
school_df_reduced
At a first glance, I noticed that there are a lot of columns in this dataset. To address this issue, I manually went through the column description list (column_descriptions.docx in my GitHub) and saved information for each column in column_filter.csv. Each row contains the following info:
- Variable: Coded representation of the survey question
- Label: Description of the survey question
- Format: Whether the answer is numerical or not
- Target: A value of 1 means the survey question is a target variable for predictions (these will not be used as features for any analysis)
- Drop: A value of 1 means that the variable is not useful in this project and will be dropped (I have chosen to drop any qualitative (opinion-based) questions or irrelevant questions)
- Binary: A value of 1 means that the variable takes on Y/N values
- Dummy: A value of 1 means that the variable is categorical but not in Y/N format (these will need to be expanded into dummy representations)
Below, I selected relevant feature columns for my analysis
cols_to_keep_df = pd.read_csv("column_filter.csv")
cols_to_keep_df.head()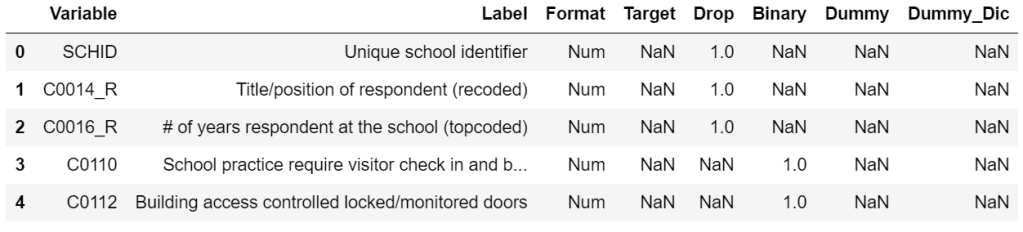
#Remove any qualitative (opinion-based) questions, irrelevant questions or target variables
cols_to_keep_df = cols_to_keep_df[(cols_to_keep_df["Drop"] != 1) & (cols_to_keep_df["Target"] != 1)]
#Use the above df to filter the full school_df
feature_df = school_df_reduced[cols_to_keep_df["Variable"]]
feature_df.head()
Next, I created a function to map the full survey question to the coded representation. This will prove handy later on when analyzing model results.
def col_description_lookup(col_list):
result = pd.DataFrame({"Variable" : col_list})
result = result.merge(cols_to_keep_df[["Variable", "Label"]], how="left", on="Variable")
return resultNext, I cleaned the remaining feature columns.
#A value of -1 represents a missing value. Convert -1 to np.nan
feature_df[feature_df == -1] = np.nan
#Create a heatmap to visualize missing values
fig, ax = plt.subplots(figsize=(20,10))
sns.heatmap(feature_df.isnull(), cbar=False, ax=ax)
In the above heatmap, white cells represent missing values. I noticed that the majority of columns have no missing values. Those that do have missing values tend to have a lot. Given that I had an abundance of feature columns, I wanted to check if it would be safe to just drop these missing value columns rather than come up with a messy imputation.
#Create a list of missing value columns
nan_cols = [col for col in feature_df.columns if feature_df[col].isnull().any()]
#Create a dataframe to see the corresponding questions
with pd.option_context('display.max_colwidth', 150, 'display.max_rows', 10):
display(col_description_lookup(nan_cols))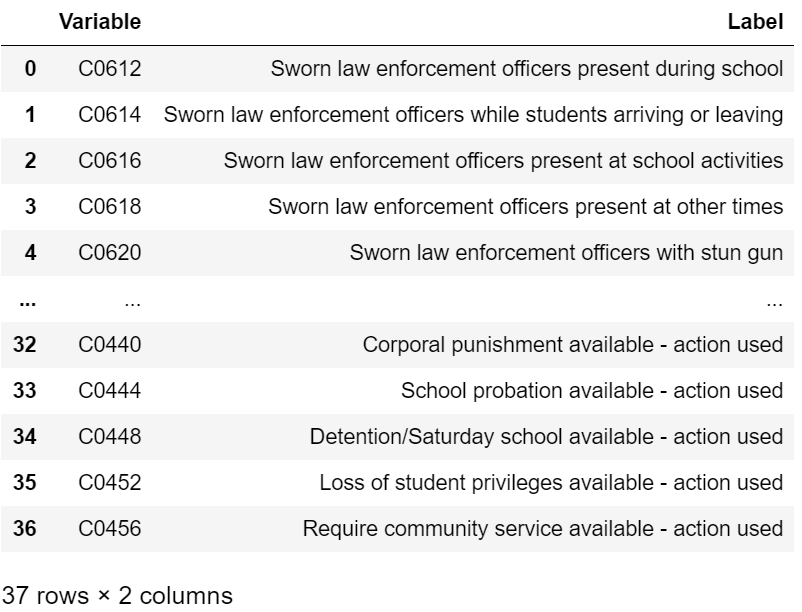
After some thought, I decided it would be best to just drop the above columns given that I had to reduce the dimensionality of my data and other questions are quite correlated with the above.
#Drop any columns with missing values
feature_df = feature_df.dropna(axis = 1)I noticed that Y/N answers were encoded as Y=1 and N=2. I chose to reencode them as Y=1 and N=0. For categorical variables with more than 2 answer choices, I created mapping to custom values, as explained below. I chose to map most of these variables into binary buckets to keep data dimensionality in check. The one exception is the PERCWHT column which I split into 4 numerical values based on the middle value of the answer bucket (see survey PDF for more details).
#Select binary columns
binary_cols = [col for col in feature_df.columns if feature_df[col].isin([1,2]).all()]
#Select non-binary columns
non_binary_cols = [col for col in feature_df.columns if not feature_df[col].isin([1,2]).all()]#Convert non-binary categorical columns to custom values
#1 if city else 0
feature_df["FR_URBAN"] = feature_df["FR_URBAN"].apply(lambda x: 1 if x==1 else 0)
#1 if high school else 0
feature_df["FR_LVEL"] = feature_df["FR_LVEL"].apply(lambda x: 1 if x==3 else 0)
#1 if >=500 students else 0
feature_df["FR_SIZE"] = feature_df["FR_SIZE"].apply(lambda x: 1 if x in [3,4] else 0)
#Convert categorical to numerical based on middle of answer bucket
feature_df["PERCWHT"] = feature_df["PERCWHT"].map({"1":97.5, "2":87.5, "3":65, "4":25})#Convert Y/N columns to 0 or 1
feature_df[binary_cols] = feature_df[binary_cols].applymap(lambda x: 1 if x==1 else 0)#Recalculate binary vs non-binary columns
binary_cols = [col for col in feature_df.columns if feature_df[col].isin([0,1]).all()]
non_binary_cols = [col for col in feature_df.columns if not feature_df[col].isin([0,1]).all()]After this data cleaning, I was still left with 109 features. Also, many of these features seemed to be redundant/correlated. Multicollinearity would make interpretation of regression models difficult so I utilized the variance inflation factor (VIF) calculation to remove highly correlated variables. I recursively eliminated the variable with the highest VIF until all remaining variables had a VIF below 5, which is the threshold commonly used in statistical literature. Given the large amount of starting columns, the below code took a while to run.
from statsmodels.stats.outliers_influence import variance_inflation_factor
def VIF_reduce(df, threshold = 5):
cols_to_keep = list(df.columns)
reduced_df = df[cols_to_keep]
vif = [variance_inflation_factor(reduced_df.values, i) for i in range(reduced_df.shape[1])]
while max(vif) >= threshold:
col_to_remove = vif.index(max(vif))
print(cols_to_keep.pop(col_to_remove) + " has been removed: VIF = " +str(max(vif)))
reduced_df = df[cols_to_keep]
vif = [variance_inflation_factor(reduced_df.values, i) for i in range(reduced_df.shape[1])]
return df[cols_to_keep]feature_df = VIF_reduce(feature_df, threshold = 5)#Recalculate binary and non-binary columns based on the VIF reduced feature df
binary_cols = [col for col in feature_df.columns if feature_df[col].isin([0,1]).all()]
non_binary_cols = [col for col in feature_df.columns if not feature_df[col].isin([0,1]).all()]After the VIF reduction, I was left with 74 feature variables. While still higher than I would have ideally liked, I chose to continue with the analysis and address feature selection as necessary in the following models.
3. Predictive Modeling
In this section, I trained several different machine learning models to see if the features from section 2 above could be used to make predictions about how many incidents of violence would occur at a US public school. I chose root mean square error (RMSE) as my primary metric for evaluating model performance, although R-squared will also be calculated for linear regression models.
3.1. Data Split and Scaling
I began by splitting my data into a train and test set, setting 20% of the entries aside as test data. In order to ensure I was able to make maximal use of my available data, I incorporated k-fold cross validation with 5 folds rather than setting aside another 20% of entries for a separate cross validation set.
#Recalculate binary and non-binary columns based on the VIF reduced feature df
binary_cols = [col for col in feature_df.columns if feature_df[col].isin([0,1]).all()]
non_binary_cols = [col for col in feature_df.columns if not feature_df[col].isin([0,1]).all()]Next, I had to standardize non-binary columns in order to ensure models would converge quickly and that the K-Nearest Neighbors algorithm would not be influeced by variable scale.
from sklearn.preprocessing import StandardScaler
#We will only scale non-binary columns
scaler = StandardScaler()
X_train_scaled = X_train
X_test_scaled = X_test
X_train_scaled[non_binary_cols] = scaler.fit_transform(X_train[non_binary_cols])
X_test_scaled[non_binary_cols] = scaler.fit_transform(X_test[non_binary_cols])
col_mean = scaler.mean_
col_std = (scaler.var_)**.5
X_test_scaled[non_binary_cols] = (X_test[non_binary_cols]-col_mean)/col_std3.2. Linear Regression
The following models incorporate variations of linear regression. First, I ran a standard OLS regression on the entire feature set. In order to address overfitting, I next constructed recursive feature elimination, ridge, and lasso regressions.
3.2.1. OLS
from sklearn.preprocessing import StandardScaler
#We will only scale non-binary columns
scaler = StandardScaler()
X_train_scaled = X_train
X_test_scaled = X_test
X_train_scaled[non_binary_cols] = scaler.fit_transform(X_train[non_binary_cols])
X_test_scaled[non_binary_cols] = scaler.fit_transform(X_test[non_binary_cols])-7.270023321646184lr.fit(X_train_scaled, y_train)
lr_coef = col_description_lookup(list(X_train_scaled.columns))
lr_coef["coef"] = lr.coef_
lr_coef = lr_coef.append({"Variable" : "INTERCEPT", "Label" : "INTERCEPT", "coef" : lr.intercept_}, ignore_index=True)
lr_coef.sort_values(by="coef")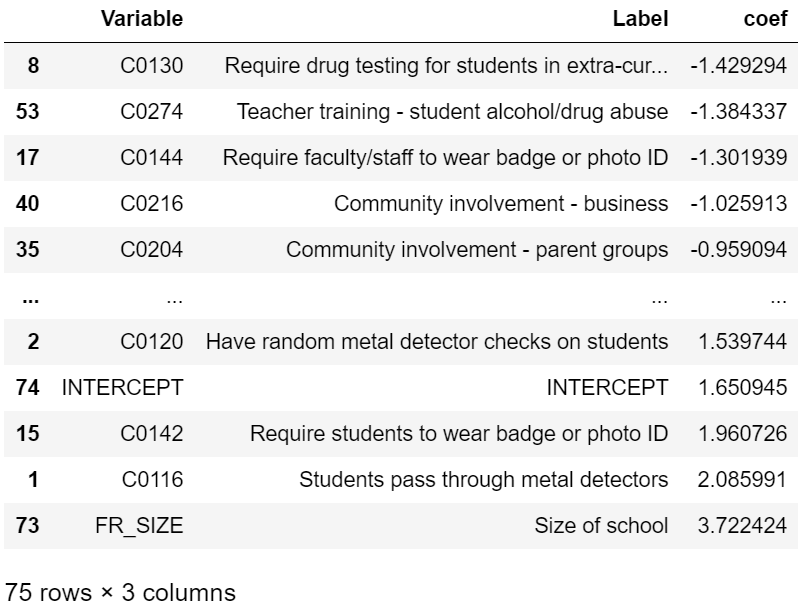
r2_lr = r2_score(y_train, lr.predict(X_train_scaled))
r2_lr0.243663610418595523.2.2. Linear Regression – OLS with Recursive Feature Elimination
from sklearn.feature_selection import RFECV
lr_rfe = LinearRegression()
selector = RFECV(lr_rfe, cv=kf, scoring="neg_root_mean_squared_error")
selector.fit(X_train_scaled,y_train)selector.n_features_24X_train_subset_scaled = X_train_scaled.iloc[:, selector.support_]
#The following calculation will prove helpful later
X_test_subset_scaled = X_test_scaled.iloc[:, selector.support_]cvs_lr_rfe = cross_val_score(lr_rfe, X_train_subset_scaled, y_train, scoring="neg_root_mean_squared_error", cv=kf)
rmse_lr_rfe = np.mean(cvs_lr_rfe)
rmse_lr_rfe-7.0246549032362395lr_rfe.fit(X_train_subset_scaled, y_train)
lr_rfe_coef = col_description_lookup(list(X_train_subset_scaled.columns))
lr_rfe_coef["coef"] = lr_rfe.coef_
lr_rfe_coef = lr_rfe_coef.append({"Variable" : "INTERCEPT", "Label" : "INTERCEPT", "coef" : lr_rfe.intercept_}, ignore_index=True)
lr_rfe_coef.sort_values(by="coef")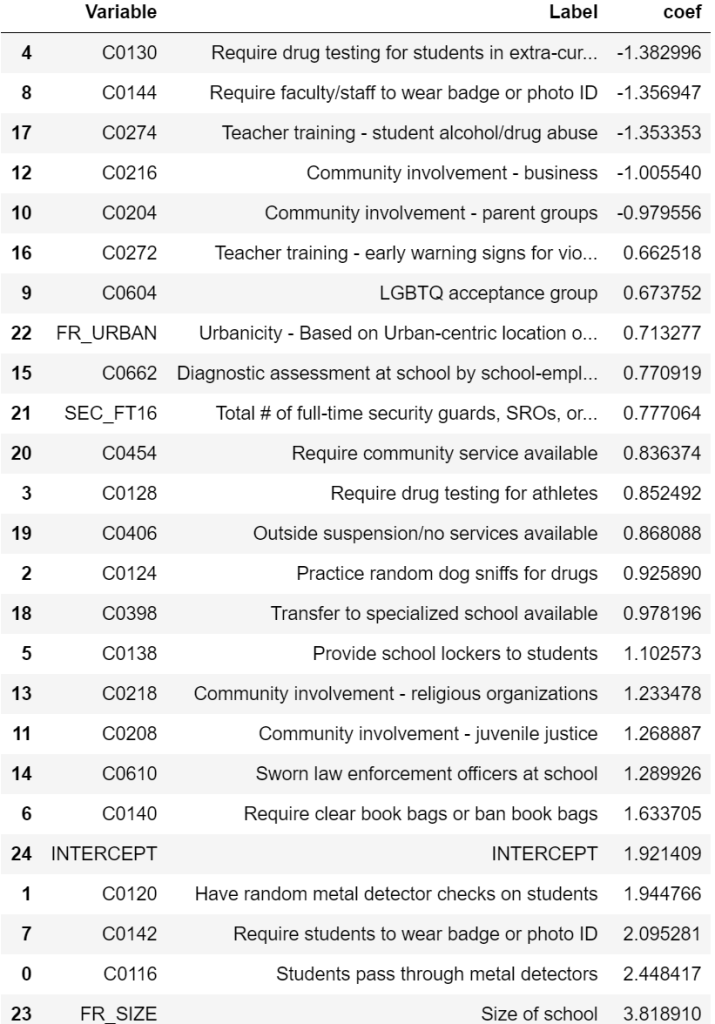
r2_lr_rfe = r2_score(y_train, lr_rfe.predict(X_train_subset_scaled))
r2_lr_rfe0.223600836477811823.2.3. Linear Regression – Ridge
While the two models above don’t incorporate hyperparameter optimization, the following regularized models require tuning of the alpha parameter. I utilized a grid search CV strategy to tune this value. Other models in this section will also take a similar approach and many involve optimizing multiple hyperparameters at once.
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import Ridge
ridge_params = {"alpha" : [.1,.3,1,3.3,10,33.3,100,333.3,1000,3333.3,10000,33333.3,100000],
"random_state" : [1]}
ridge = Ridge()
ridge_grid = GridSearchCV(estimator=ridge,
param_grid=ridge_params,
scoring="neg_root_mean_squared_error",
cv=kf)
ridge_grid.fit(X_train_scaled, y_train)ridge_grid.best_params_{'alpha': 100, 'random_state': 1}ridge_grid.best_score_-7.147173041344463ridge = ridge_grid.best_estimator_
r2_ridge = r2_score(y_train, ridge.predict(X_train_scaled))
r2_ridge0.233209275785220333.2.4 Linear Regression – Lasso
from sklearn.linear_model import Lasso
lasso_params = {"alpha" : [.1,.3,1,3.3,10,33.3,100,333.3,1000,3333.3,10000,33333.3,100000],
"random_state" : [1]}
lasso = Lasso()
lasso_grid = GridSearchCV(estimator=lasso,
param_grid=lasso_params,
scoring="neg_root_mean_squared_error",
cv=kf)
lasso_grid.fit(X_train_scaled, y_train)lasso_grid.best_params_{'alpha': 0.1, 'random_state': 1}lasso_grid.best_score_-7.1150815488163675lasso = lasso_grid.best_estimator_
r2_lasso = r2_score(y_train, lasso.predict(X_train_scaled))
r2_lasso0.21482661046120932lasso_coef = col_description_lookup(list(X_train_scaled.columns))
lasso_coef["coef"] = lasso.coef_
#Remove features that were eliminated by lasso
lasso_coef = lasso_coef[lasso_coef["coef"] != 0]
lasso_features = lasso_coef["Variable"]
lasso_coef = lasso_coef.append({"Variable" : "INTERCEPT", "Label" : "INTERCEPT", "coef" : lasso.intercept_}, ignore_index=True)
lasso_coef.sort_values(by="coef")
3.3. K-Nearest Neighbors
While the above linear regression results seemed okay, I wanted to see if other ML models would result in better performance. I next built a KNN model. The main issue was that with 74 variables, my feature set had far too large dimensionality for KNN to make much sense as points become very sparse in high-dimensional space. To address this, I constructed a separate model on two subsets of variables: the RFE feature set and the lasso feature set.
3.3.1. KNN on RFE Feature Set
from sklearn.neighbors import KNeighborsRegressor
knn_params = {"n_neighbors" : [2,4,8,16,32,64,128,256,512],
"weights" : ["uniform", "distance"],
"p" : [1,2]}
knn = KNeighborsRegressor()
#To avoid the curse of dimensionality, I used the features selected from OLS RFE
knn_rfe_grid = GridSearchCV(estimator=knn,
param_grid=knn_params,
scoring="neg_root_mean_squared_error",
cv=kf)
knn_rfe_grid.fit(X_train_subset_scaled, y_train)knn_rfe_grid.best_params_{'n_neighbors': 64, 'p': 2, 'weights': 'uniform'}knn_rfe_grid.best_score_-7.1263937957900793.3.2. KNN on Lasso Feature Set
#Next, I reran the above process on the features selected from lasso
knn_lasso_grid = GridSearchCV(estimator=knn,
param_grid=knn_params,
scoring="neg_root_mean_squared_error",
cv=kf)
knn_lasso_grid.fit(X_train_scaled[lasso_features], y_train)knn_lasso_grid.best_params_{'n_neighbors': 64, 'p': 2, 'weights': 'distance'}knn_lasso_grid.best_score_-7.2226491743410743.4. Random Forest
from sklearn.ensemble import RandomForestRegressor
rf_params = {"n_estimators" : [100],
"max_depth" : [2,4,8,16,32,64,128,None],
"max_features" : ["sqrt", "log2", .1, .25, .5, 5, 10, 25],
"random_state" : [10]}
rf = RandomForestRegressor()
rf_grid = GridSearchCV(estimator=rf,
param_grid=rf_params,
scoring="neg_root_mean_squared_error",
cv=kf)
rf_grid.fit(X_train_scaled, y_train)rf_grid.best_params_{'max_depth': 8, 'max_features': 0.25, 'n_estimators': 100, 'random_state': 10}rf_grid.best_score_-7.0325179371165823.5. Neural Network
Given the computational requirements of multi-layer neural networks, the following block of code took quite some time to run.
rf_grid.best_scorefrom sklearn.neural_network import MLPRegressor
nn_params = {"hidden_layer_sizes" : [(100,),(100,100)],
"activation" : ["logistic", "tanh", "relu"],
"alpha" : [.0001,.001,.01,.1,1.0,10,100,1000],
"max_iter" : [2500],
"random_state" : [10],
"warm_start" : [True]}
nn = MLPRegressor()
nn_grid = GridSearchCV(estimator=nn,
param_grid=nn_params,
scoring="neg_root_mean_squared_error",
cv=kf,
verbose=2)
nn_grid.fit(X_train_scaled, y_train)nn_grid.best_params_{'activation': 'tanh',
'alpha': 100,
'hidden_layer_sizes': (100,),
'max_iter': 2500,
'random_state': 10,
'warm_start': True}nn_grid.best_score_-7.1432365963797313.6. Model Selection and Interpretation
The results of the above models are summarized in the table below (ordered from best to worst performance):
models = ["Linear Regression - OLS",
"Linear Regression - OLS w/ RFE",
"Linear Regression - Ridge",
"Linear Regression - Lasso",
"K-Nearest Neighbors - RFE",
"K-Nearest Neighbors - Lasso",
"Random Forest",
"Neural Network"]
optimized_parameters = ["N/A",
{"n_features": selector.n_features_},
ridge_grid.best_params_,
lasso_grid.best_params_,
knn_rfe_grid.best_params_,
knn_lasso_grid.best_params_,
rf_grid.best_params_,
nn_grid.best_params_]
RMSEs = [-rmse_lr,
-rmse_lr_rfe,
-ridge_grid.best_score_,
-lasso_grid.best_score_,
-knn_rfe_grid.best_score_,
-knn_lasso_grid.best_score_,
-rf_grid.best_score_,
-nn_grid.best_score_]
R2 = [r2_lr,
r2_lr_rfe,
r2_ridge,
r2_lasso,
"N/A",
"N/A",
"N/A",
"N/A"]
model_df = pd.DataFrame({"model" : models,
"optimized_parameters" : optimized_parameters,
"R2" : R2,
"RMSE" : RMSEs})
with pd.option_context('display.max_colwidth', 150):
display(model_df.sort_values(by="RMSE"))
Based on RMSE, the performance of all models was fairly similar. When it comes to model selection, there is often a tradeoff between performance and interpretability. Interestingly, the model with the lowest RMSE (OLS with RFE) is also quite easy to interpret.
Drug testing, required faculty ID, teacher training on substance abuse, and community involvement in school safety were all associated with a reduction in violent incidents. Not surprisingly, larger schools (FR_SIZE = 1) were associated with more violent incidents. Less expected was that metal detectors, required student IDs, required clear book bags/book bag bans, presence of law enforcement, etc. were associated with an increase in violent incidents. This seems like a classic case of correlation not implying causation. For example, schools with measures as stringent as requiring students to pass through metal detectors likely already have a history of school violence which resulted in those measures being instated.
Next, I wanted to check the significance of the calculated coefficients. Below, I used a separate module to calculate p-values and confidence intervals. The majority of these coefficients were statistically different from 0 (can reject the null-hypothesis).
import statsmodels.api as sm
model = sm.OLS(y_train, sm.add_constant(X_train_subset_scaled))
model_fit = model.fit()
significance_df = model_fit.summary2().tables[1]
significance_df["reject_null"] = significance_df["P>|t|"].apply(lambda x: 1 if x<.05 else 0)
significance_df.sort_values(by="Coef.")
Now, I wanted to analyze how model error varied depending on the value of the target variable. As shown below, residuals were generally more negative for y_train < 10 (model prediction was too high) and more positive for y_train > 10 (model prediction was too low). This suggests that there may be some different dynamics at play between the data in each group (which could potentially be addressed by the addition of polynomial/interaction features.
y_train_pred = lr_rfe.predict(X_train_subset_scaled)
residuals = y_train-y_train_pred
fig, ax = plt.subplots(figsize = (12,9))
plt.scatter(y_train, residuals)
One byproduct of linear regression is that it can predict negative values even when such a prediction does not make real-world sense. In fact, some schools with 0 violent incidents were predicted as having negative incidents. As a final adjustment to the OLS with RFE model, I adjusted any negative predictions to output 0 instead. Below is a cross-validated simulation of the model. Given that only a few predictions were negative, this final model only gives marginal improvement.
from sklearn.metrics import mean_squared_error
cvs_final_model = []
for train_index, cv_index in kf.split(X_train_subset_scaled):
x_train_temp, x_cv = X_train_subset_scaled.iloc[train_index], X_train_subset_scaled.iloc[cv_index]
y_train_temp, y_cv = y_train.iloc[train_index], y_train.iloc[cv_index]
lr_rfe.fit(x_train_temp,y_train_temp)
y_pred = lr_rfe.predict(x_cv)
#Adjust negative predictions to 0
y_pred = [y if y>0 else 0 for y in y_pred]
rmse = mean_squared_error(y_cv, y_pred)**.5
cvs_final_model.append(rmse)
np.mean(cvs_final_model)7.022960908337237Finally, for an unbiased estimate of how this model would perform on unseen data, I fit it on the whole training set (ignoring CV folds) and calculated a final RMSE value for the test set.
lr_rfe.fit(X_train_subset_scaled, y_train)
y_pred = lr_rfe.predict(X_test_subset_scaled)
y_pred = [y if y>0 else 0 for y in y_pred]
rmse = mean_squared_error(y_test, y_pred)**.5
rmse7.8223653668973614. Conclusion/Further Steps
While the OLS RFE model did show some modest promise in making predictions about violent incidents, it can clearly be improved. The RMSE of 7.82 on the test set is quite high given that the range of violent incidents for the schools studied was 0 to 31. However, the statistical significance of the model features suggests that these inputs are useful.
As a first additional step, I would focus on reducing model bias and bringing the k-fold RMSE value down to a more reasonable number. This can be accomplished in a variety of ways:
- Introduce interaction/polynomial features
- Get additional data on the schools in this survey
- Precise number of students in each school
- More granular demographic information (ethnicity, religion, political)
- Geographical location (state, city, etc.)
- Get additional data about the area surrounding the school
- Weapon laws/sales
- Precise crime rate
Unfortunately, this survey anonymized responses, so it isn’t currently possible to gather additional data corresponding to an individual school. However, the SSOCS has also been conducted during several other years in the past, and it would be interesting to see how the temporal component affects violent incidents and whether any trends have appeared over time.
